Page 1 of 1
Cyrillic search is case sensitive
Posted: Sat Dec 22, 2018 6:22 pm
by rokot108
Hello!
I noticed, that with English alphabet searching for an intem in inventory menus is not case-sensitive. But in Russian version all searchings for Russian-named items are case-sensitive, and it makes inconvenience every time, when i need to find an intem in a menu.
Usually, i just drop a first letter of the item's name, cause it may be of any kind.
Re: Cyrillic search is case sensitive
Posted: Sun Dec 23, 2018 1:13 am
by Rseding91
Thanks for the report however I don't think this will change. We don't have any language-agnostic system for converting a character to lowercase and so non-English characters have this issue.
Re: Cyrillic search is case sensitive
Posted: Sun Dec 23, 2018 7:42 am
by TruePikachu
Is `std::tolower` not sufficient for this when provided with a suitable locale?
Re: Cyrillic search is case sensitive
Posted: Sun Dec 23, 2018 6:31 pm
by Rseding91
TruePikachu wrote: Sun Dec 23, 2018 7:42 am
Is `std::tolower` not sufficient for this when provided with a suitable locale?
Nope. std::tolower only supports single-character values - no UTF support.
Re: Cyrillic search is case sensitive
Posted: Sun Dec 23, 2018 6:43 pm
by Optera
To get any multibyte support you have to use a multibyte aware container, std::string is not multibyte aware.
A more sane solution would be to use an unicode library for any string that can be unicode, for C++ i guess that'd be ICU
http://site.icu-project.org/
Re: Cyrillic search is case sensitive
Posted: Mon Dec 24, 2018 4:42 am
by TruePikachu
Modern C++ (and C, for that matter)
does have native Unicode support.
`std::basic_string` and its derivatives aren't
naturally multibyte variable-length-character aware, but by using e.g. `std::u32string` ≡ `std::basic_string<char32_t>` for string storage you can avoid the problems of variable-length characters, or by using e.g. `std::codecvt<char32_t, char, std::mbstate_t>` as a conduit for converting UTF-8 to and from UCS-4, one can keep the memory savings of using UTF-8 while still being able to resolve UCS-4 codepoints.
EDIT: Just did some testing, Windows doesn't appear to like doing locale-based case conversions in UCS-4, but everything is fine when using `wchar_t` as the intermediate (which is UCS-2 under Windows, and likely sufficient):
Code: Select all
#include <iomanip>
#include <iostream>
#include <locale>
#include <string>
using namespace std;
locale::id codecvt<char32_t,char,mbstate_t>::id;
int main() {
locale::global(locale("en_US.utf8"));
// UTF-8 encoded string
string data = u8"\uff26\uff21\uff23\uff34\uff2f\uff32\uff29\u2699";
cout << "UTF-8:";
for(auto c : data) {
cout << " 0x" << uppercase << hex << setw(2) << setfill('0')
<< static_cast<int>(static_cast<uint8_t>(c));
}
cout << endl;
// Conversion to wide string, not using C++17 depreciated functionality
auto& facet = use_facet<codecvt<wchar_t,char,mbstate_t>>(locale());
wstring wide(data.size(),'\0');
mbstate_t state = {};
const char* d_next;
wchar_t* w_next;
facet.in(state,
&data[0], &data[data.size()], d_next,
&wide[0], &wide[wide.size()], w_next);
wide.resize(w_next - &wide[0]);
cout << "Wide: ";
for(auto c : wide)
cout << " 0x" << uppercase << hex << setw(4) << setfill('0') << c;
cout << endl;
cout << "Lower:";
for(auto c : wide)
cout << " 0x" << uppercase << hex <<setw(4) << setfill('0')
<< tolower(c,locale());
return 0;
}
Code: Select all
UTF-8: 0xEF 0xBC 0xA6 0xEF 0xBC 0xA1 0xEF 0xBC 0xA3 0xEF 0xBC 0xB4 0xEF 0xBC 0xAF 0xEF 0xBC 0xB2 0xEF 0xBC 0xA9 0xE2 0x9A 0x99
Wide: 0xFF26 0xFF21 0xFF23 0xFF34 0xFF2F 0xFF32 0xFF29 0x2699
Lower: 0xFF46 0xFF41 0xFF43 0xFF54 0xFF4F 0xFF52 0xFF49 0x2699
("FACTORI⚙" if anyone's curious)
Re: Cyrillic search is case sensitive
Posted: Mon Dec 24, 2018 10:19 am
by Optera
That's interesting, I guess my C is a bit rusty.
Re: Cyrillic search is case sensitive
Posted: Wed May 08, 2024 4:19 pm
by Hares
This bug hurts me a lot. I end up searching science packs and other items/settings as "cience pack", "ogistics requests", "oboport", etc. since sometimes the main word is not the 1st one (i.e., Russian's name for SE rocket science is "Science pack of rocketry" while other are "... science pack". I hope this would be fixed in 2.0.
Re: Cyrillic search is case sensitive
Posted: Tue Nov 05, 2024 7:18 pm
by Osmo
This is still an issue in version 2.0.15, and with Space Age, it is much more impactful. For example depending on which letter you start with, the Iron or Copper plate recipes will either show up as regular smelting or foundry smelting.
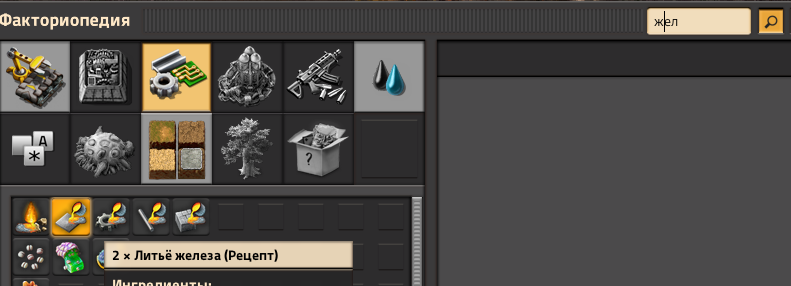
- изображение.png (106.21 KiB) Viewed 2897 times
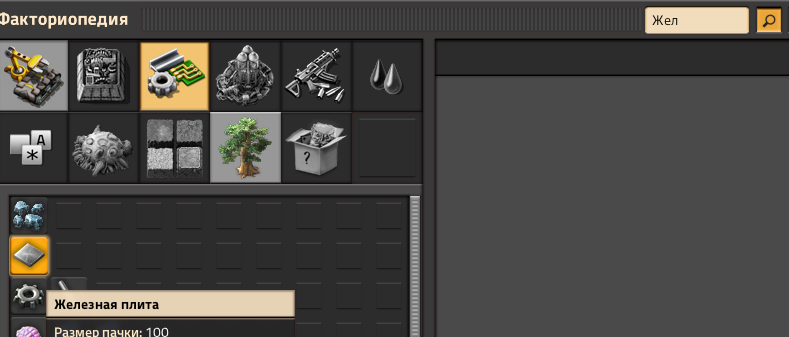
- изображение.png (94.52 KiB) Viewed 2897 times
It is incredibly inconvenient, and it should be possible to use a different or custom function to turn letters lowercase that will fix search everywhere for a large portion of users who don't use Latin.
Re: Cyrillic search is case sensitive
Posted: Thu Nov 07, 2024 9:44 am
by xargo-sama
I didn't want to comment until I was 100% this was making it in, but I will be sharing some good news tomorrow regarding this.
Re: Cyrillic search is case sensitive
Posted: Thu Nov 07, 2024 4:50 pm
by DeltaKilo
Not the OP, but finally. Thank you very much!
Are other languages like Greek also case insensitive after this change?