What an interesting discussion, too bad I'm late to the party.
One thing I want to mention first: I love how open the devs are with respect to the code, algorithms etc. Please keep that up! I'm certain the game benefits in the end - and it's also educational for us.
There is one thing about parallelization that seems was not clearly mentioned yet:
Scientific simulation
Factorio is in essence a discrete simulation on a 2D grid. Most interactions are local. That makes it very similar to all kinds of scientific simulations, be it particle simulations, weather, computation fluid dynamics, you name it. In that sense it is ideal for a domain decomposition on sub-grids (e.g. chunks). I have said that already at the initial multithreading-FF and I am glad to see that the discussion is going in the right direction.
Now I'm not particularly sure about the 3x3 generation parallelization. For once I'm not really use I understand the approach correctly: I take it that chunks within the same generation are considered independent and can be executed by threads in parallel. I further assume this will lead to some irregularities at chunk borders, possibly changing the priority e.g. of inserters depending on the order of generations (in order to avoid double buffering).
My fear about this processing is, that it might loose a lot of data locality. In essence every border exchange will not be cached because the respective neighbor-chunk was/or will be processed far in the past/future. In order to reduce the amount of data that has to be exchanged, a decomposition can look like this:
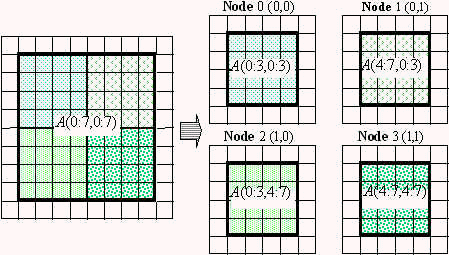
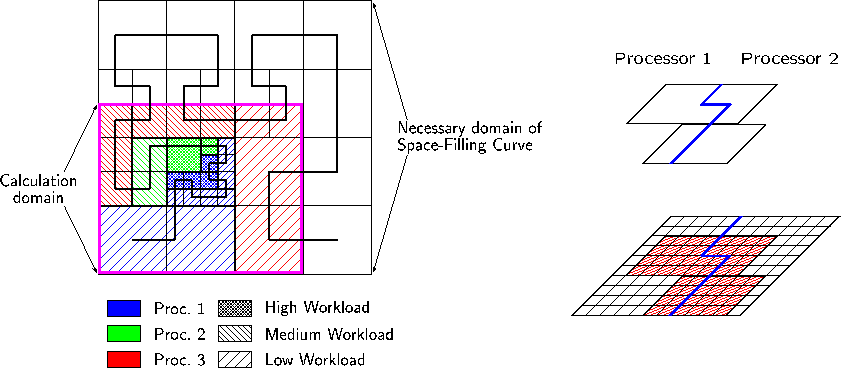
Of course that won't work well if your megabase is in the top right corner, but then there are many load balancing techniques, for instance using a space-filling-curve and a workload metric to assign chunks:
Or keeping it even simpler, why process only complete rows of chunks in parallel and make only two generations: even and odd Y-numbers. That way, at least half of the data exchange is now between chunks that will be processed after each other.
In general, my feeling is that chunks are too small for dynamic scheduling (as Harkonnen also indicates), and larger subgrids would still expose enough parallelism. That said, I do recognize that chunks are probably an integral part of the general optimizations. BTW: I wouldn't call them single-threaded optimizations, just because they don't have anything to do with multithreading. A multithreaded Factorio can just as well benefit from those optimizations.
By the way, game of life was mentioned before and a interesting code example was shown. I'd like to show how this would be done with scientific computing methods, namely OpenMP:
Code: Select all
#pragma omp parallel
for (curgen = 0; curgen < gens_max; curgen++)
{
#pragma omp for
for (t = 0; t < nrows*ncols; t++)
{
int i = t / ncols;
int j = t % ncols;
const int inorth = mod (i-1, nrows);
const int isouth = mod (i+1, nrows);
const int jwest = mod (j-1, ncols);
const int jeast = mod (j+1, ncols);
const char neighbor_count =
BOARD (ingrid, inorth, jwest) +
BOARD (ingrid, inorth, j) +
BOARD (ingrid, inorth, jeast) +
BOARD (ingrid, i, jwest) +
BOARD (ingrid, i, jeast) +
BOARD (ingrid, isouth, jwest) +
BOARD (ingrid, isouth, j) +
BOARD (ingrid, isouth, jeast);
BOARD(outgrid, i, j) = alivep (neighbor_count, BOARD (ingrid, i, j));
}
SWAP_BOARDS( outgrid, ingrid );
}
(by
saeedn on stackoverflow.com)
I'm interested to hear what you think which approach is easier

. In any case, I don't say the Factorio devs are dumb/lazy/ignorant. In fact I consider them among the brightest programmers in the industry. However, I do see little bit of a tendency towards reinventing the wheel. And I don't think they should switch all code to OpenMP and PETSc. However, I can only encourage you to take a look at techniques used in scientific computing and learn from that. I have no idea how hard it will be to apply these techniques to the factorio codebase, but the problem lends itself very well to be a parallel simulation.
An interesting anecdote about game of life is, that the best optimization actually comes from hashing subgrids, which allows huge simulations. Unfortunately I don't think that is feasible with the slightly more complex ruleset of Factorio.
Brownout scenario
Power calculation is among the challenges when it comes to global effects. I do think this can be overcome: For instance changing the internal power to use binary on/off and allow single-tick energy debts/buffers. Some care has to be taken when merging/splitting electricity networks so that one cannot create free energy with combinator/power switches.
Memory optimization
It seems very much that there is still huge potential for optimization by using better memory layouts to improve locality. I would agree that the devs should focus on those. But while those improvements don't necessarily conflict with parallelization, it can be more effort to add parallelization as an aferthought.
Anyway I am very interested in taking a deeper look at Factorio performance, but I don't want to do that on 0.14. So I hope the experimental builds will soon be available again.
Oh and for
multi-process-factorio, there
is already a mod,.